
Companion long-form on X — read the X Article version
Working in EU financial services? Pair this with our DORA Article 28 register guide for AI vendors — same evidence pipeline, different supervisor.
Key Takeaways
- August 2, 2026 is the hard deadline for high-risk AI obligations under Annex III. Hiring, credit, healthcare triage, critical infrastructure, justice, migration. If your LLM touches any of these, the clock has nearly run out.
- Article 15 is the technical wall. "Accuracy, robustness, cybersecurity" is what notified bodies actually push on. Software-only controls rarely survive that conversation.
- TDX attestation is the cleanest Article 15 evidence currently shippable. A cryptographically-signed Intel quote settles the tampering-resistance prong in one artifact.
- Penalties scale to 3% of global turnover for high-risk non-compliance. For most mid-market firms that is a board-level number, not an IT line item.
Most teams I talk to in April 2026 are in one of two states. Either they have not started on the EU AI Act because "August feels far," or they have started and they are stuck on Article 15. Both states share a root cause: the Act is being read as a documentation exercise. It is not. It is a technical conformity regime, and the technical bar is higher than most in-house counsels were briefed to expect.
I wrote this so a CTO, a Head of Compliance, or a regulated-sector founder can read it once and walk away with three things: a clear picture of who is in scope, a working definition of Article 15 evidence, and a path that does not require burning Q3 on rework. Some of what follows is uncomfortable. The Act is genuinely hard, the deadlines are real, and the fines are not theatre. Better to know now.
Who Is Actually In Scope
The Act regulates the use-case, not the model. A general-purpose Llama-3.1 deployment is not automatically high-risk. The same Llama-3.1 deployed to screen CVs for a hiring pipeline is. Annex III enumerates the eight high-risk categories. As of February 2026 Commission guidance, the practical map looks like this:
- Employment: hiring, performance evaluation, task allocation, promotion, termination decisions assisted by AI.
- Education and vocational training: admissions, grading, exam-cheating detection, behavioural monitoring of students.
- Access to essential services: credit scoring, insurance pricing, social benefits, emergency services dispatch.
- Critical infrastructure: safety components in road traffic, water, gas, electricity, healthcare devices.
- Law enforcement: predictive policing, evidence reliability assessment, profiling.
- Migration, asylum, border control: risk assessment, document verification, lie-detection equivalents.
- Administration of justice and democratic processes: anything assisting judicial decision-making or election integrity.
- Biometric identification: real-time and post-event, plus emotion recognition in workplaces and schools.
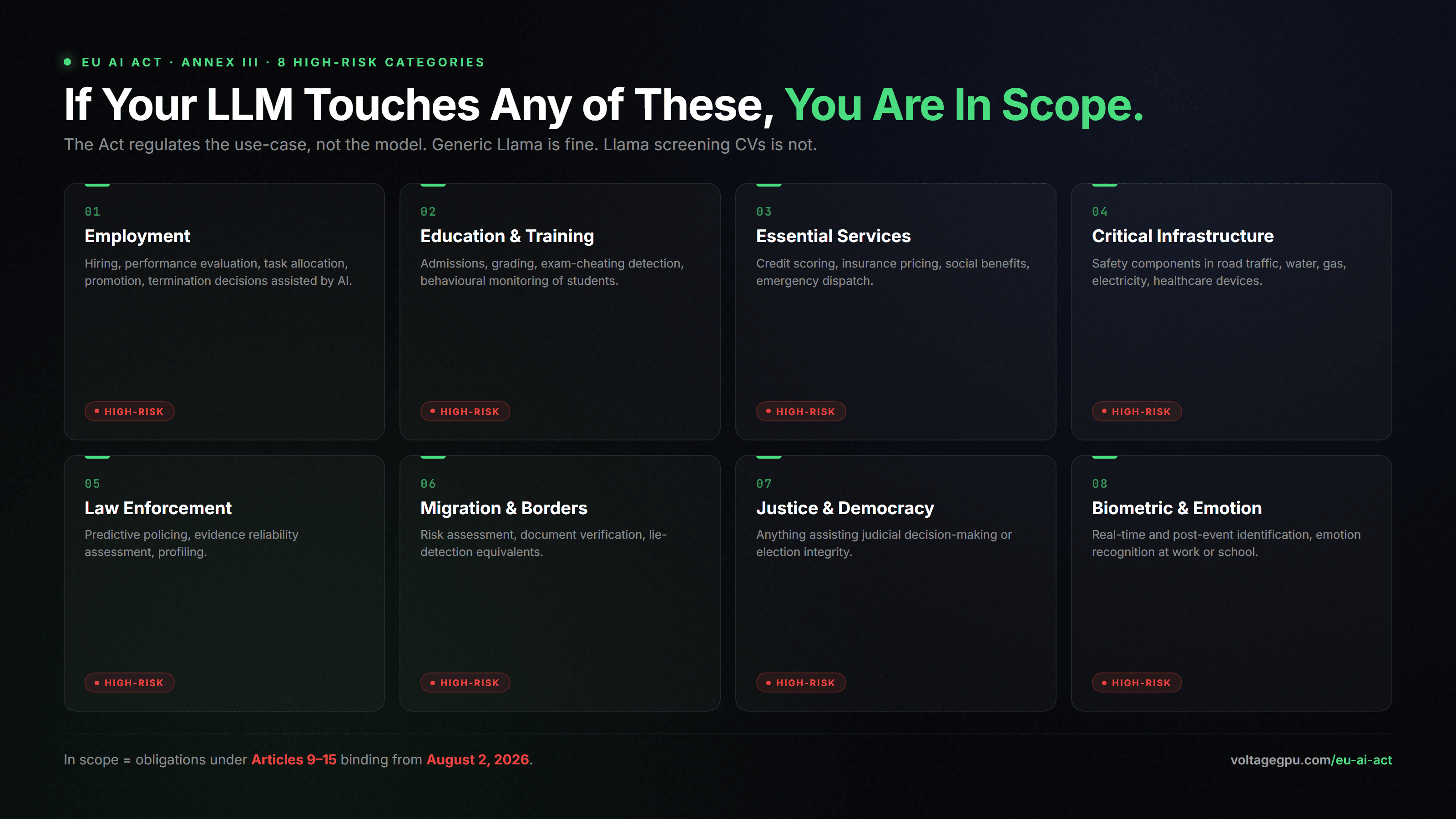
If you are running an LLM behind any of the above, you are a provider or deployer of a high-risk system — the two roles have different duties, but both are bound by the August 2026 timeline. The fastest self-check most legal teams use:
# Quick Annex III high-risk self-check (compressed).
# If ANY answer is yes, your LLM use-case is in scope of the August 2026 deadline.
scenarios = [
"Does your LLM influence access to education, employment, or promotions?",
"Does it score creditworthiness, insurance pricing, or social benefits?",
"Does it triage emergency calls, healthcare, or critical infrastructure?",
"Does it support law enforcement, migration, asylum, or border control?",
"Does it inform judicial decisions or democratic processes?",
"Does it perform biometric identification or emotion recognition at work/school?",
]
if any_yes(scenarios):
print("HIGH-RISK under Annex III. Article 9-15 obligations apply by 2026-08-02.")
print("You need: risk management, data governance, technical docs,")
print("logging, transparency, human oversight, and Article 15 cybersecurity.")The Articles That Actually Bite
On paper, providers of high-risk AI systems must satisfy Articles 9 through 15. In practice, three of them are where audits live or die:
- Article 10 — Data and Data Governance. Training, validation, and test datasets must be relevant, representative, free of obvious errors, and complete. For LLM fine-tunes this means a documented data lineage. Most teams have this in some form already from GDPR Article 30 records.
- Article 14 — Human Oversight. The system must be designed so a human can intervene meaningfully. This is operational, not just documentary — your UI has to let a reviewer override or revoke a decision before it has effect.
- Article 15 — Accuracy, Robustness, and Cybersecurity. The third prong — cybersecurity — is where confidential computing has become the de-facto answer. The Act demands resistance to third-party attempts to alter use, behaviour, or performance. A privileged hypervisor reading model weights or rewriting a system prompt at runtime is exactly the threat model the Article was drafted against.
The Act also weaves through GDPR Article 32 territory when personal data is involved. Both regimes converge on the same conclusion: vendor promises are not evidence; cryptographic attestation is.
What Article 15 Evidence Actually Looks Like
Article 15(5) requires "technical solutions to address AI-specific vulnerabilities, including measures to prevent, detect, respond to, resolve and control for attacks trying to manipulate the training dataset (data poisoning), pre-trained components used in training (model poisoning), inputs designed to cause the AI model to make a mistake (adversarial examples or model evasion), confidentiality attacks or model flaws."
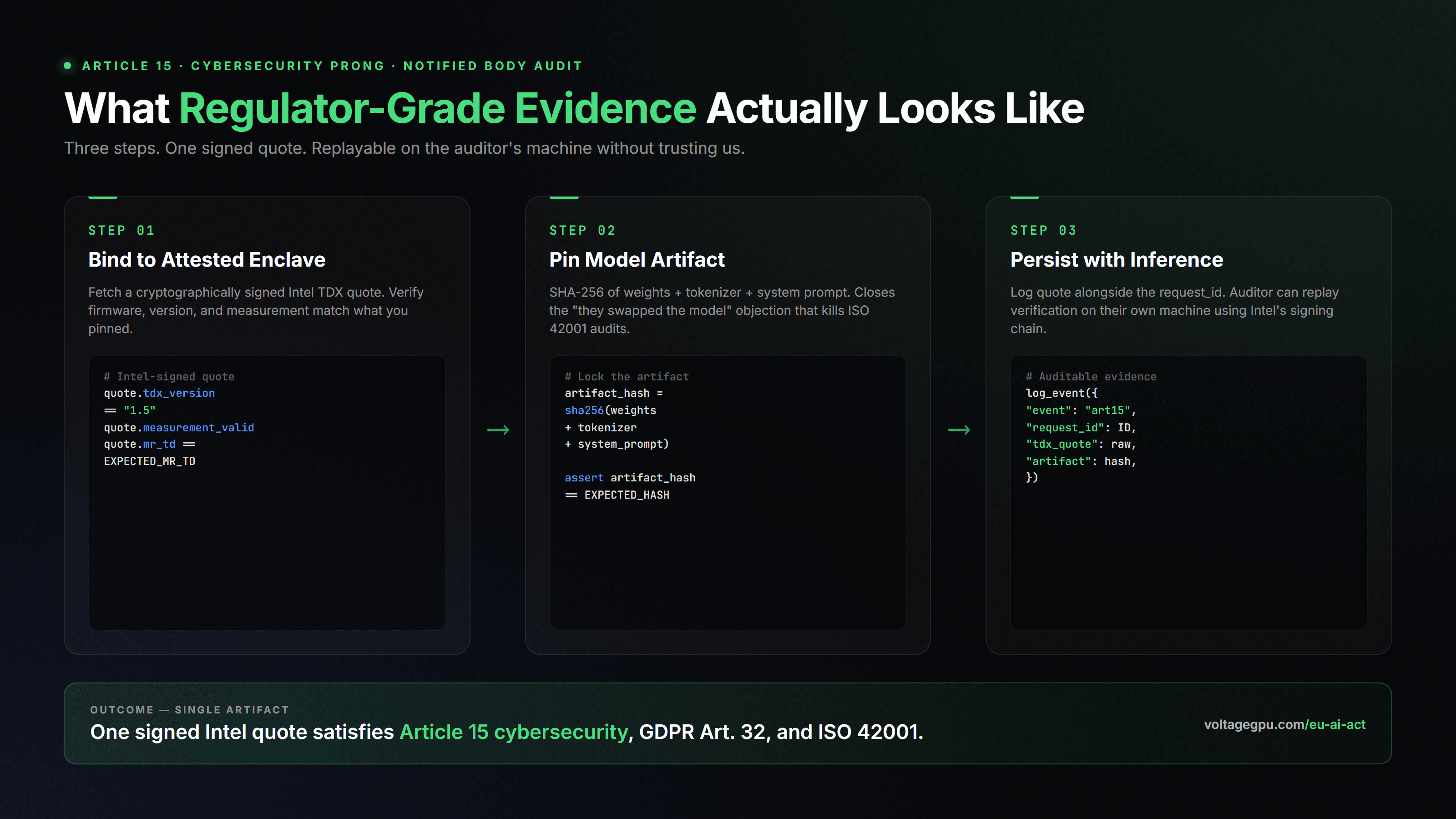
Operationally, the workflow we ship to compliance teams is roughly twenty lines of Python:
import requests, hashlib
# Article 15 ("accuracy, robustness, cybersecurity") evidence pipeline.
# A signed Intel TDX attestation quote satisfies the cybersecurity prong
# in a way that no software-only vendor can.
quote = requests.get(
"https://api.voltagegpu.com/v1/pods/POD_ID/attestation",
headers={"Authorization": "Bearer vgpu_YOUR_KEY"},
).json()
# 1. Bind the workload to a measured, attested enclave.
assert quote["tdx_version"] == "1.5"
assert quote["measurement_valid"] is True
assert quote["mr_td"] == EXPECTED_MR_TD
# 2. Pin the model artifact: weights + tokenizer + system prompt.
artifact_hash = hashlib.sha256(open("model.safetensors", "rb").read()).hexdigest()
assert artifact_hash == EXPECTED_ARTIFACT_HASH
# 3. Persist the quote alongside the inference id. This is your
# auditable, regulator-grade Article 15 evidence.
log_event({
"event": "ai_act_art15_attested_inference",
"request_id": REQUEST_ID,
"tdx_quote": quote["raw_quote"],
"artifact_hash": artifact_hash,
})
print("Article 15 evidence captured. Notified body audit-ready.")Two things that workflow gives you that nothing else currently does. First, the attestation quote is regulator-replayable: the CNIL or BfDI auditor can verify the Intel signature on their own machine without trusting us. Second, the artifact-hash binding pins thespecific model and prompt template to the inference call, which closes the "but they could swap the model after the fact" objection that has killed several ISO 42001 audits I have seen.
Penalty Math, Without the Theatre

Two practical notes. SMEs and startups receive the lower of the two caps, not the higher — a deliberate Commission concession to avoid extinction-level fines for smaller actors. And the percentage is calculated on the group worldwide turnover for the preceding financial year, not the relevant subsidiary's. For mid-market financial services, that is the difference between a manageable line item and a board-level event.
A Practical Roadmap For The Next 90 Days

- Map your in-scope systems. Use the Annex III checker. For each yes, declare provider vs deployer status. This is a one-week exercise for a typical mid-market firm.
- Stand up technical documentation per Annex IV. Most of it is recyclable from your existing model cards plus GDPR Article 30 records. Budget two to three weeks.
- Move inference for in-scope systems behind an attested enclave. This is where most teams underestimate effort. With VoltageGPU TDX pods the lift is essentially a one-line change to your inference base URL plus a quote-verification step in your pipeline. With Azure Confidential Computing it is heavier and roughly four times the unit price.
- Wire human-oversight controls into the UI. Reviewer override, audit trail, hard stop on confidence-below-threshold cases. Article 14 is the easiest article to fail on default ChatGPT-style deployments.
- Engage a notified body early. The ones that matter for AI under Annex III are visibly oversubscribed for Q3 2026 already. Get on the calendar now even if your evidence pack is not ready — the relationship discount on rework is real.
What This Article Does Not Solve (Pratfall, Honest Edition)
I would rather you know the limitations now than discover them mid-audit:
- Confidential computing does not replace human oversight. Article 14 is operational. If your application does not let a human meaningfully intervene, no attestation quote will save you.
- It does not produce model-card or data-governance evidence. Article 10 still wants a documented data lineage. TDX seals execution, not provenance.
- Notified body availability is the real bottleneck. Most of the regulatory-grade audit firms are quoting Q4 2026 onboarding right now. Plan accordingly.
- The Act is still being interpreted. The Commission, EDPS, and national authorities are issuing guidance on a rolling basis through 2026. Build for the spirit of Article 15 (verifiable tamper-resistance) rather than chasing every paragraph.
Who Should Read This Twice
- Heads of Compliance and DPOs at EU regulated firms operating in financial services, healthcare, HR-tech, legal-tech, edtech, and gov-tech.
- CTOs and platform leads who built an internal LLM gateway in 2024-2025 and now need to bring it to AI Act conformity.
- Founders of B2B AI products selling into Annex III use-cases — your buyers will increasingly require AI Act evidence as part of vendor onboarding from mid-2026.
Two starting points if you want to go deeper: our confidential computing primer for the architecture, and the GDPR & AI 2026 piece for the privacy-side of the same conversation.
FAQ
When exactly does the EU AI Act apply to high-risk systems?
Is my LLM automatically high-risk?
What does Article 15 ("accuracy, robustness, cybersecurity") actually require?
How do penalties work?
Does GDPR Article 32 evidence count for AI Act Article 15?
Get an AI-Act-grade pod in under 60 seconds
Pull a TDX attestation quote yourself and see what regulator-grade evidence actually looks like. $5 referral credit, no credit card, EU-pinned by default.